![[ 4 -1 ] 인덱스 기본 원리 / Balanced Tree ( B Tree)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FbXPDan%2Fbtq0UdFcXWf%2FAAAAAAAAAAAAAAAAAAAAAJKKuojsvkiGP6rCDYCMeXo0HHlBckrhCvsjeT3srxIr%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1772290799%26allow_ip%3D%26allow_referer%3D%26signature%3DUQURsLIIbgSe7mYNDHYk84A6xOw%253D)
인덱스는 우리가 흔히 아는 색인이라고 생각을 하면 이해가 조금더 빠를 수 있다가. 가나다 순이고 키워드가 같을 땐 페이지 순으로 찾는다. 이처럼 좀 빨리 찾고 싶을 때 우리가 색인을 이용하는 것처럼 데이터 베이스도 인덱스로 DBMS 도 찾는다. root 노드가
1. 인덱스 기본 구조
인덱스 기본 구조의 노드는 -> B* Tree 가 일반적.이다. 이 처럼 정말 나무를 뒤집어 놓았으므로 맨 위쪽 뿌리를 설정해줄 수 있으며 해당 루프, 브랜치 , 리프까지 모두 갖춘 노드를 의미한다.
ROWID : 테이블 레코드를 찾아가기 위해 필요한 주소 정보
키 값이 같을 경우에는 ROWID 순으로 정렬된다는 사실 ~~
이는 정방향 스캔과 역방향 스캔이 둘다 가능하도록 양방향 연결 리스트 ( Double Linked List) 구조로 연결함.
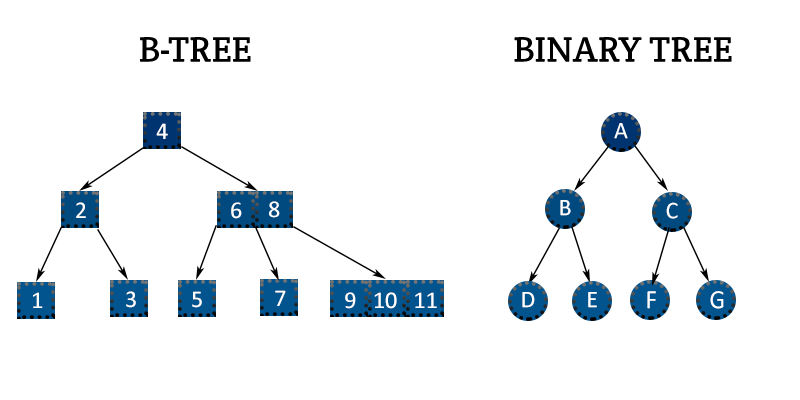
B-Tree 와 Binary Tree
* B- Tree : 자식 노드의 개수가 2개 이상인 트리를 말함. 또한 이처럼 위의 부모 노드는 자식의 노드를 정렬시키는 기준이 되며 노드 기준보다 데이터가 작은 값은 왼쪽에~ 그리고 데이터가 큰 값은 오른쪽에 위치 된다.
- B-tree: stores keys in its internal nodes but doesn’t need to store those keys in the records at the leaves.
- B+ tree: copies of the keys are stored in the internal nodes while the keys and records are stored in leaves; in addition, a leaf node may include a pointer to the next leaf node which speeds the sequential access.
- B* tree: keep the internal nodes more densely packed by balancing more neighbouring internal nodes. This ensures non-root nodes are fuller – 2/3 instead of 1/2.
( 참고 : open4tech.com/b-tree-vs-binary-tree/ )
2. 인덱스 탐색
- 수평적 탐색
* 인덱스 리프 블록에 저장된 레코드 끼리 연결된 순서에 따라 좌에서 우 또는 우에서 좌로 스캔
- 수직적 탐색
* 루트에서 리프 블록까지 아래쪽으로 진행하기 때문에 수직적이다.
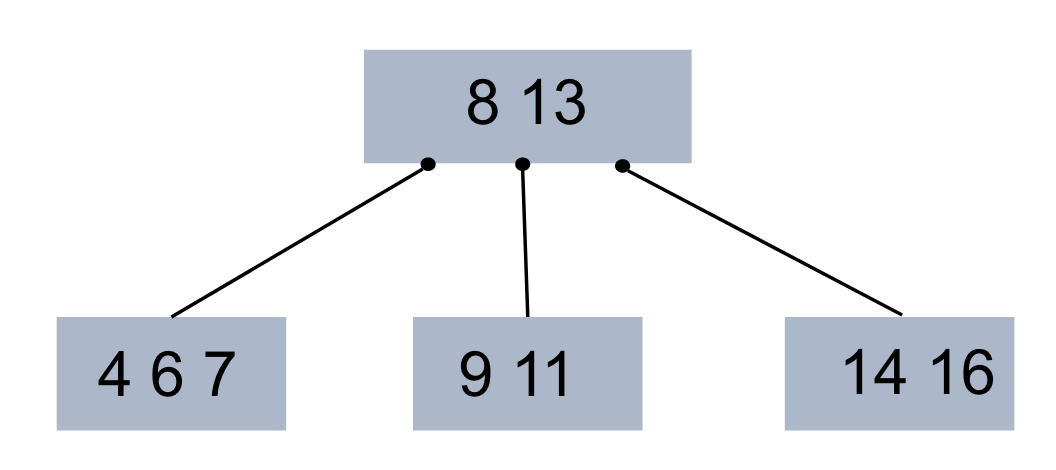
우선 ) B+Tree 와 B* Tree 에 대해서 몇가지 조건이 존재.
인덱스와 키가 존재하고 해당 조건이 몇개의 키까지 하나의 노드에 저장되는지 정해진다.
해당 노드가 우선 정해지고 그다음에 삽입이 되거나 삭제가 될 때 몇가지 rule 에 따라 움직인다.
[ 삽입 이 되는 경우 ]
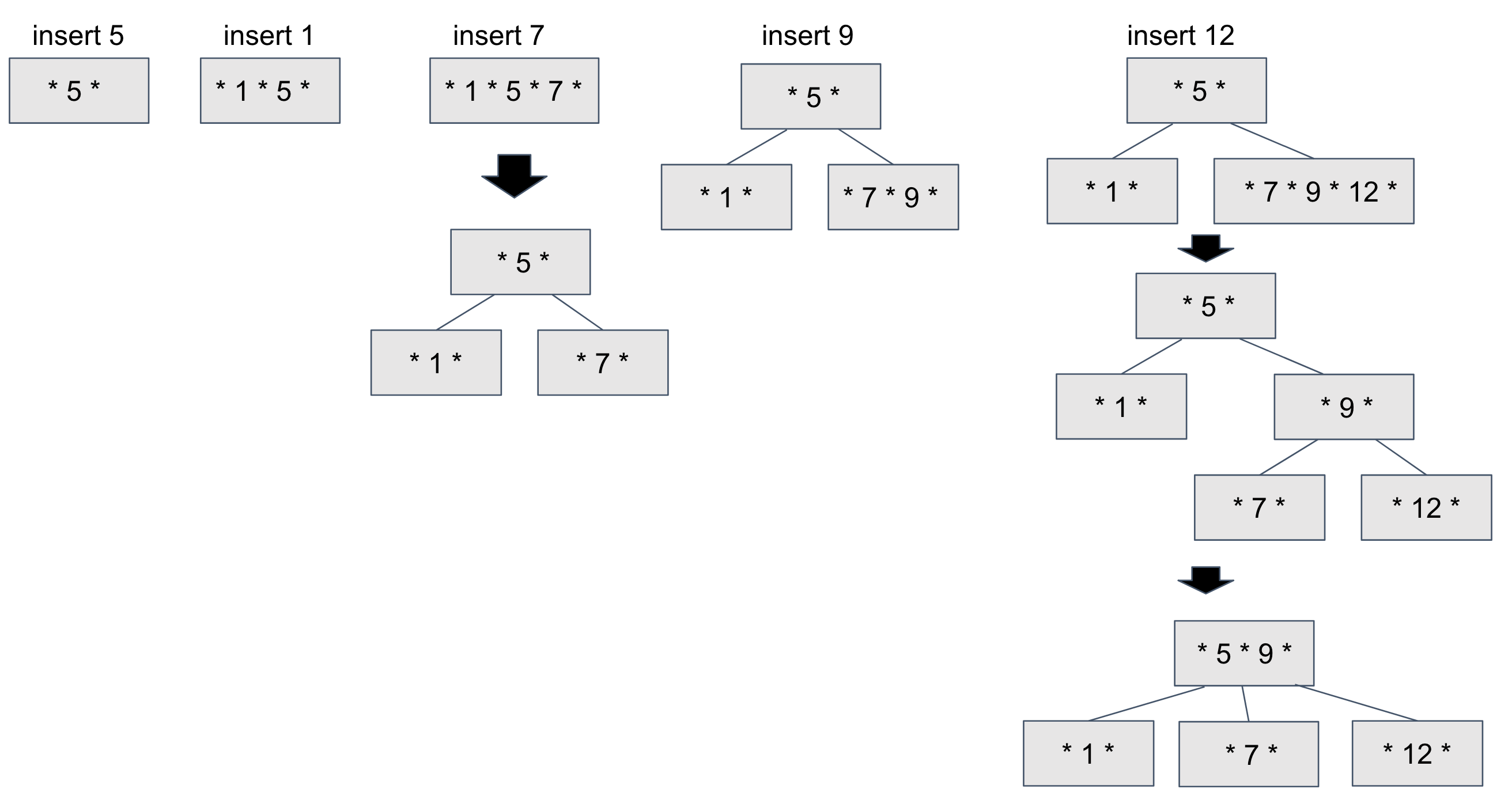
B+ 성립 조건에 따라서 삽입이 된다.
* 노드의 데이터수가 n개라면 자식 노드의 개수는 n+1 개
* 노드의 데이터는 반드시 정렬된 상태
* 노드의 자식노드의 데이터들은 노드 데이터를 기준으로 데이터보다 작은 값은 왼쪽 서브 트리에 큰값들은 오른쪽 서브 트리
* Root 노드가 자식이 있다면 2개이상의 자식
* Root 노드를 제외한 모든 노드는 적어도 M/2 개의 데이터를 가져야 함. 3차 B-Tree 는 1 개의 노드 / 4 차 B-Tree 는 2개 이상의 노드를 가져야함.
* Leaf 노드로 가는 경로의 길이가 같아야함. Leaf 노드는 모두 같은 레벨에 존재
정말 B Tree 에 대해서 잘 설명한 것 같은 블로그 링크!
hyungjoon6876.github.io/jlog/2018/07/20/btree.html
B-Tree 개념 정리
데이터베이스와 파일시스템에서 B-Tree를 많이 사용합니다. rdb 인덱스 관련해서 정리해보다가 일반적으로 B-Tree , B+-Tree 자료구조를 사용하는것을 알게되었습니다. B-Tree 자료 구조에 대해서 알아
hyungjoon6876.github.io
[MySQL] B-Tree 인덱스
인덱스는 데이터베이스 쿼리의 성능을 언급하면서 빼놓을 수 없는 부분입니다. MySQL에서 사용 가능한 인덱스의 종류 및 특성에서 각 특성의 차이는 상당히 중요하며, 물리 수준의 모델링을 할
12bme.tistory.com
'이유's Programming > DBMS' 카테고리의 다른 글
| [ 4 - 3] 인덱스 종류 (0) | 2021.03.31 |
|---|---|
| [ 4 -2 ] 인덱스 스캔 방식 - (0) | 2021.03.25 |
| SQL 연산자 (0) | 2021.03.23 |
| [ 3 -1 ] DBMS 내장 함수 (0) | 2021.03.19 |
| [ 식별자 ] 본질식별자와 인조식별자 (0) | 2021.03.18 |